LLaMA-Factory 使用
LLaMA-Factory 使用

安装 LLaMA-Factory
首先先去 github 上 clone LLaMA-Factory 项目到本地
git clone https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
pip install -e .[torch,metrics]
#.[]中可以填写{torch, metrics, deepspeed, bitsandbytes, vllm, galore, badam, gptq, awq, aqlm, qwen, modelscope, quality}
# 按需填写,比较推荐直接把vllm和modelscope下载了.
因为我是单卡(多卡的话就不能用 webui),所以直接运行的是 webui 的部分,比较直观也比较好调参数,具体开启代码在LLaMA-Factory/src/llmtuner/webui里,LLaMA-Factory/src/llmtuner/webui/interface.py中
def run_web_ui() -> None:
create_ui().queue().launch() #.launch()中可以添加server_port=port指定gradio开启的窗口
输入命令
CUDA_VISIBLE_DEVICES=0 GRADIO_SHARE=1 llamafactory-cli webui
或者直接新建一个脚本
from src.llmtuner.webui.interface import run_web_demo, run_web_ui
import os
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
if __name__ == "__main__":
run_web_ui()
用来开启 webui
配置 LLaMA-Factory
为了方便下载模型直接加了这个脚本,具体可以去 modelscope 里找
# 模型下载
from modelscope import snapshot_download
model_dir = snapshot_download("ZhipuAI/chatglm3-6b", revision = "v1.0.0", cache_dir='models')
"""
model_id = {'baicai003/Phi-3-mini-128k-instruct-Chinese',
'LLM-Research/Phi-3-mini-4k-instruct',
'ChineseAlpacaGroup/llama-3-chinese-8b-instruct',
"ZhipuAI/chatglm3-6b", revision = "v1.0.0"}
"""
# "ZhipuAI/chatglm3-6b", revision = "v1.0.0"
运行 webui 后打开 gradio 界面如下
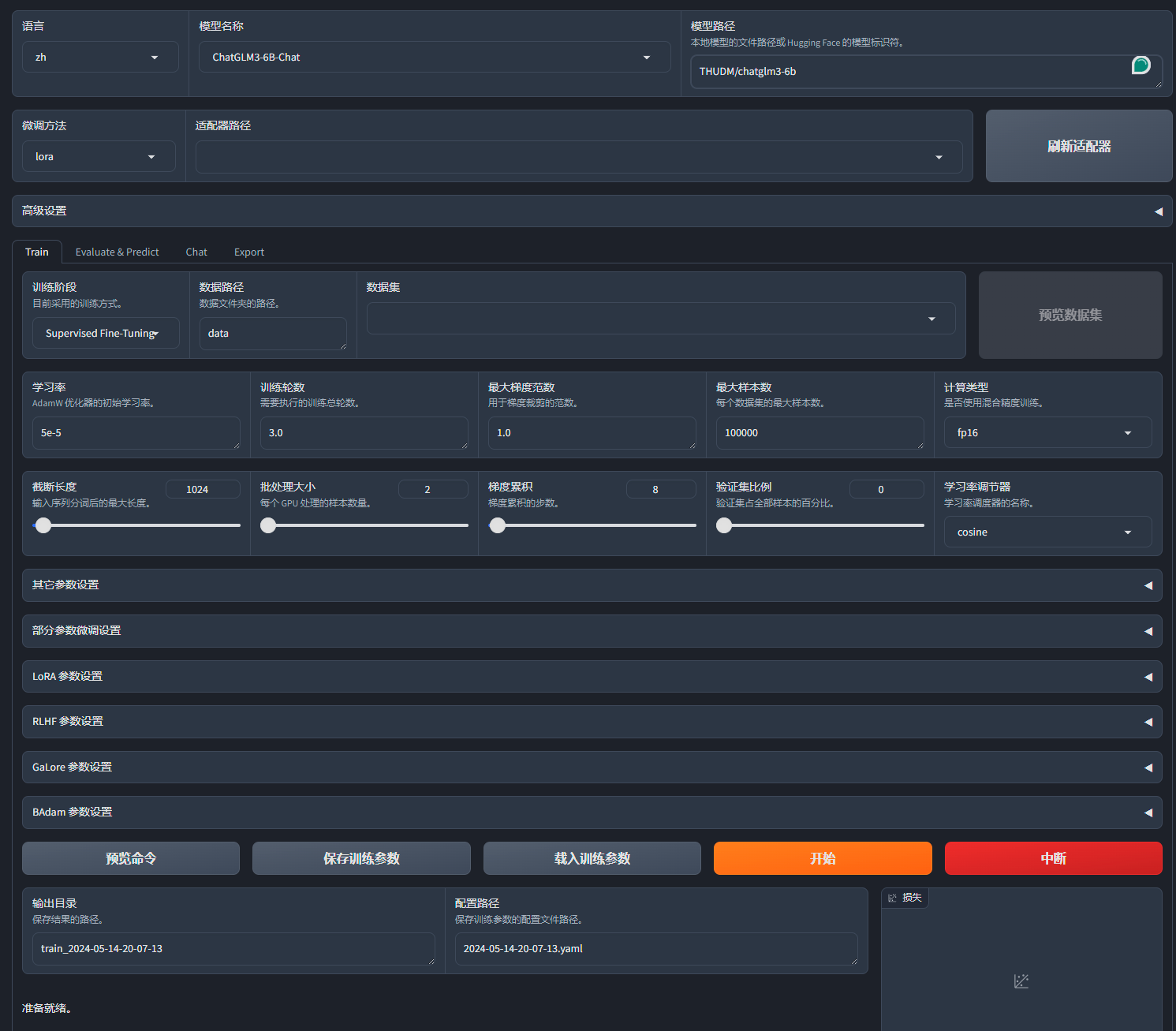
训练模型
- 模型路径就是 models 的下载位置,按照上面的脚本会直接下载在 models 文件夹下
- 数据集的话我都是以以下格式然后还需要到
LLaMA-Factory/data/dataset_info.json中根据格式填写。[ { "instruction": "", "input": "", "output": [""] }, { "instruction": "", "input": "", "output": [""] }, { "instruction": "", "input": "", "output": [""] } ]"geo_signal": { "file_name": "geo_signal.json", "file_sha1": "32633118B240079DA7C8D2C244978311AB4AE0E0" }Get-FileHash -p "file_path" -Algorithm SHA1 - 然后就可以在数据集里找到刚刚添加的数据集,接下来就是训练部分,默认使用 lora
一般以 loss 降低到 0.5 为目标,训练阶段就是微调,然后学习率就按默认,我训练次数比较小时会跳到 5e-4,如果数据集够大,训练轮数一般 3 次以内就够了,目标就是让 loss 降到 0.5 左右,如果显存够用可以把 batch_size 调高,此时 lr 也应该相对应加大一点点,理论上现在就可以直接预览命令然后开始训练了。
如果不使用 webui 也可以按照 webui 中给出的预览命令进行修改
使用模型进行预测
训练完成后可以去 Chat 中,选择适配器,名字就是输出目录里的名字,加载模型后就可以聊天,然后要是效果好就可以直接导出
多卡训练
多卡训练的我没用过,具体可以参考LLaMA-Factory 的 README 文件